(posting this in Data Quality to begin with…)
The IATI Rulesets are a set of conditions that it would be very useful for any IATI publisher to consider in their publication.
These are not enforced at the schema level, but additional. Think of these rules as the bits of “guidance” you often see in the IATI schema, which are then represented as rules to help us use them! They represent logic (eg start date before end date!) and conditions (percenrages of multiple countries should add to 100%) and other things!
These rulesets are very important, and have long been available around IATI. We know that they are not currently used in the “official IATI validator”, but are used by others. At Open Data Services, we use the rulesets in our tools, for example.
Who else uses the rulsets? Rolf Kleef Roderick Besseling John Adams maybe?
Looking at the current IATI rules, and in discussion with others such as Yohanna Loucheur Herman van Loon Rob Redpath (IATI Secretariat) & Andy Lulham , there seem to be a couple of omissions, which I would suggest we incorporate:
Sectors
There is no rule in terms of multiple sectors from the same vocabulary should add to 100%. The standard text says:
All reported sectors from the same vocabulary MUST add up to 100.
There is no rule in the ruleset for this
Policy Markers
There is no rule in terms of conditions of the Policy Marker codes
The standard says:
Policy Significance code = 4 (Explicit primary objective) SHOULD ONLY be used in conjunction with Policy Marker code = 9 (Reproductive, Maternal, Newborn and Child Health)
There is no rule in the ruleset for this
==================
There may be others too - so I wonder if there is chance to get a wider review of these rulesets…?
{kind=link}
It appears to be the following:
For instance, here’s an activity in d-portal with 10 sectors, adding up to 1,000%:
Screen Shot 2018-07-17 at 22.11.33.png908×370 57 KB
ref.
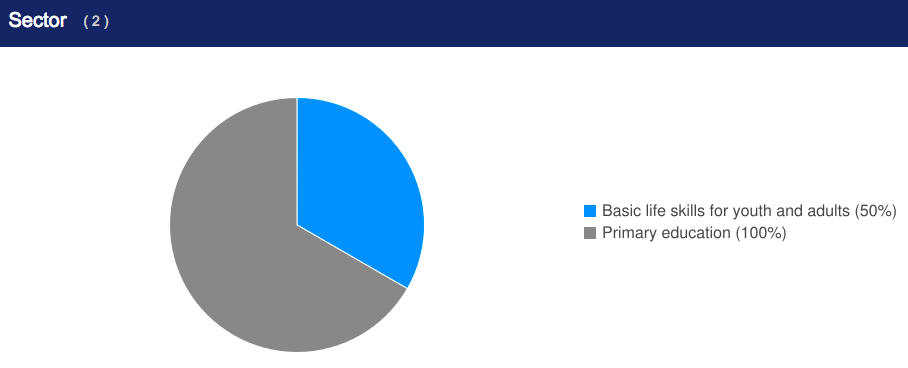
Here’s one with 2 sectors adding up to 50%:
Screen Shot 2018-07-17 at 22.27.54.png912×366 14.5 KB
ref.
recipient-country and recipient-region have their own issues! But we should probably save that for a separate discussion.
thanks Andy Lulham for the detective work - I guess I can see the logic in the second approach - stick to the given numbers (but as you say, the pie chart should really only show 50% accounted for) - as for the first one - no comment!
Thanks, Andy Lulham - yup, that’s what we’ve done.
If you don’t specify a number, we will treat it as 100% so this way, when multiple sectors are not given a percentage, we are still able to rescale the pie chart and they all get an equal share.
We basically treat the numbers as ratios.
Once we’ve got all of the sectors, we add them up and if it comes to more or less than 100%, we adjust it so it adds up to 100% by scaling; ie. if it adds up to 200%, we half it to fit.
If the numbers don’t add up to 100%, we attribute this to a data quality issue.
The original numbers are displayed in SAVi.
In d-portal, yes. We can’t split the money unless it all adds up to 100% so we always make sure it adds up to that.
If people are publishing the right numbers, this would not be a problem but when they don’t, we make a ‘best guess’. Otherwise, we will not be able to include that activity in the portal.
Ultimately, these graphs are not just visual representations of the data, we also use these calculated percentages for the rest of d-portal; ie. all the sector and publisher tables.
This means, the whole site is dependant on the quality of the data that has been published.
Thanks, Andy Lulham - yup, that’s what we’ve done.
If you don’t specify a number, we will treat it as 100% so this way, when multiple sectors are not given a percentage, we are still able to rescale the pie chart and they all get an equal share.
We basically treat the numbers as ratios.
Once we’ve got all of the sectors, we add them up and if it comes to more or less than 100%, we adjust it so it adds up to 100% by scaling; ie. if it adds up to 200%, we half it to fit.
If the numbers don’t add up to 100%, we attribute this to a data quality issue.
The original numbers are displayed in SAVi.
In d-portal, yes. We can’t split the money unless it all adds up to 100% so we always make sure it adds up to that.
If people are publishing the right numbers, this would not be a problem but when they don’t, we make a ‘best guess’. Otherwise, we will not be able to include that activity in the portal.
Ultimately, these graphs are not just visual representations of the data, we also use these calculated percentages for the rest of d-portal; ie. all the sector and publisher tables.
This means, the whole site is dependant on the quality of the data that has been published.